📊 Full opportunity report: VigilSAR Benchmark: There Is No Best Model on ThorstenMeyerAI.com — validation score, market gap, and execution plan.
TL;DR
The VigilSAR Benchmark demonstrates that no AI model is best across all defense-related axes. Rankings depend on specific user profiles, emphasizing the importance of context in model selection. This shifts focus from capability alone to trustworthiness and deployability.
The VigilSAR Benchmark has confirmed that there is no single best AI model for defense-relevant tasks. Its findings emphasize that model rankings depend heavily on the specific needs and constraints of the user, such as deployment environment, compliance, and reliability. This challenges the common narrative that the top-ranked model on capability leaderboards is universally superior, highlighting the importance of context in AI deployment decisions.
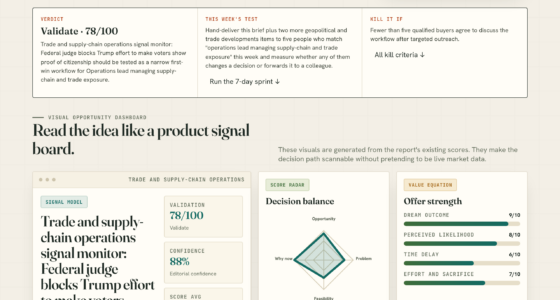
The VigilSAR Benchmark evaluates models across five axes: Capability, Reliability, Robustness, Safety & Compliance, and Efficiency & Deployability.Learn more about the VigilSAR Benchmark. Unlike traditional leaderboards that focus solely on raw performance, VigilSAR explicitly considers deployment scenarios relevant to defense and regulated environments. The benchmark scores models on eight knowledge domains and then re-ranks them based on three buyer profiles: cloud-centric, sovereign edge, and compliance-first. The results show that a model highly ranked in one profile may fall significantly in another, underscoring that ‘best’ is relative to specific operational needs.
According to the developers, the benchmark intentionally excludes offensive or harmful capabilities, focusing instead on trustworthy, defense-relevant competence. It also prioritizes safety and compliance, emphasizing that models must meet strict regulatory standards to be considered suitable for deployment. For a detailed discussion, see the VigilSAR Benchmark overview. The methodology remains in development, with ongoing refinements expected as the approach evolves. You can explore related insights in our VigilSAR Benchmark article.
VigilSAR Benchmark — there is no best model
Capability leaderboards measure who’s smartest. This one scores who’s deployable — across five axes — then re-ranks by who’s actually asking.
Independent commentary, produced with AI assistance under human editorial oversight. The views are the author’s own and may change. VigilSAR Benchmark is an early-stage, in-development public benchmark; methodology, scope and results will evolve and are not a certification, authority, or guarantee of any model’s fitness, safety, or compliance. It scores defense-relevant competence and explicitly excludes weaponeering, targeting, CBRN, and exploit-generation tasks. Benchmark results are indicative, can be gamed or in error, and require independent verification; nothing here endorses any model. Model and company names are trademarks of their respective owners; mention does not imply endorsement.
Implications of No Universal Model for Defense AI
This finding shifts the paradigm in AI procurement and deployment for defense and regulated sectors. It underscores that selecting an AI model requires careful consideration of deployment environment, regulatory compliance, and reliability, rather than relying solely on capability scores. For organizations, this means adopting a more nuanced, context-aware approach to AI procurement, reducing the risk of choosing models that are unsuitable for their specific operational constraints. It also highlights the importance of transparency and trustworthiness in AI development, especially in sensitive applications where safety and compliance are paramount.

Hands-On Guide to the Model Context Protocol: Building, Securing, and Scaling AI Agents in Python (The Hands-On Tech Professional Series Book 29)
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Background on Model Benchmarking and Defense AI Evaluation
Traditional AI leaderboards have primarily focused on measuring models’ raw performance on a set of tasks, often emphasizing intelligence and problem-solving ability. However, these rankings do not account for practical deployment factors such as on-premises operation, regulatory compliance, robustness, or safety. The VigilSAR Benchmark was developed to fill this gap by evaluating models in a defense-relevant context, considering real-world constraints that influence whether a model can be effectively and safely deployed in sensitive environments.
Previous assessments have often led to a misconception that the top-ranked model on capability leaderboards is the best choice overall. VigilSAR challenges this assumption by demonstrating that rankings vary significantly depending on the user’s operational profile, such as cloud-based versus sovereign, air-gapped deployment. The benchmark’s multi-axis approach aims to provide a more comprehensive view of model suitability for defense applications.
“There is no one-size-fits-all model for defense, because deployment context matters more than raw capability.”
— Thorsten Meyer, VigilSAR Developer

Adversarial AI Attacks, Mitigations, and Defense Strategies: A cybersecurity professional's guide to AI attacks, threat modeling, and securing AI with MLSecOps
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Uncertainties in Benchmark Methodology and Scope
The VigilSAR Benchmark is still in development, and its methodology may evolve as further refinements are made. It currently does not assess offensive or harmful capabilities, focusing solely on trustworthy, defense-relevant knowledge. It remains unclear how future updates might change rankings or incorporate additional axes such as adversarial robustness or long-term reliability. Furthermore, the full impact of the varying profiles on model selection in real-world scenarios is still being studied, and practical deployment decisions will need to consider additional factors not captured by the benchmark.

AI Forensics
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Next Steps in Benchmark Development and Adoption
The VigilSAR team plans to continue refining its methodology, expanding the scope to include more models and knowledge domains. They aim to collaborate with defense and industry stakeholders to validate the benchmark’s relevance and usability. Future updates are expected to clarify how models perform under different operational constraints and to develop more tailored recommendations for specific user profiles. Organizations interested in deploying AI for defense should monitor these developments and consider multi-profile evaluations to inform their procurement processes.
robust AI models for regulated environments
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Key Questions
Why is there no single ‘best’ AI model for defense applications?
Because the suitability of an AI model depends on specific deployment constraints, compliance requirements, and operational environments, making a universal ranking impractical and potentially misleading.
What axes does the VigilSAR Benchmark evaluate?
It assesses models on Capability, Reliability, Robustness, Safety & Compliance, and Efficiency & Deployability, across eight knowledge domains.
How does the benchmark account for different user needs?
It re-ranks models based on three profiles—cloud, sovereign edge, and compliance-first—showing that rankings vary depending on deployment context.
Is the VigilSAR Benchmark complete or still evolving?
It is currently in active development, with ongoing updates expected to refine its methodology and expand its scope.
Does the benchmark evaluate harmful or offensive capabilities?
No, it explicitly excludes offensive or harmful capabilities, focusing instead on trustworthy, defense-relevant knowledge and compliance.
Source: ThorstenMeyerAI.com